Every modern business depends on moving data efficiently — from applications and APIs to analytics dashboards and machine learning models. This is where data pipeline architectures come in.
A data pipeline architecture is the design of how data is collected, moved, transformed, and stored from multiple sources into a central system, such as a data warehouse, data lake, or application database.
At a high level, data pipelines fall into two main categories:
- Batch pipelines – process data in chunks at scheduled intervals.
- Streaming pipelines – process data continuously in real time or near real time.
In addition, new approaches like Zero-ETL, Data Sharing, and Data Mesh are reshaping how organisations think about data pipelines.
Batch Data Pipeline Architectures
Batch pipelines move data in groups at scheduled times (hourly, daily, weekly). They are reliable, widely used, and ideal when real-time insights are not required.
ETL (Extract → Transform → Load)
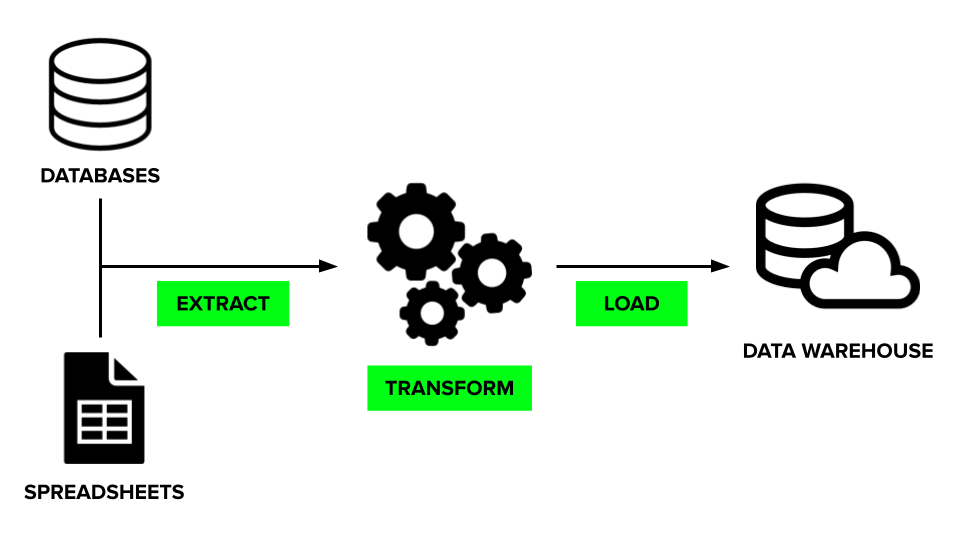
- How it works: Data is extracted from multiple sources, then cleaned, standardised, and transformed before being loaded into the target system. Transformations often include aggregations, filtering, and joining data to match business logic. This approach ensures only high-quality, structured data is delivered for analytics and reporting.
- Best for: Traditional reporting, BI dashboards, financial data.
ELT (Extract → Load → Transform)
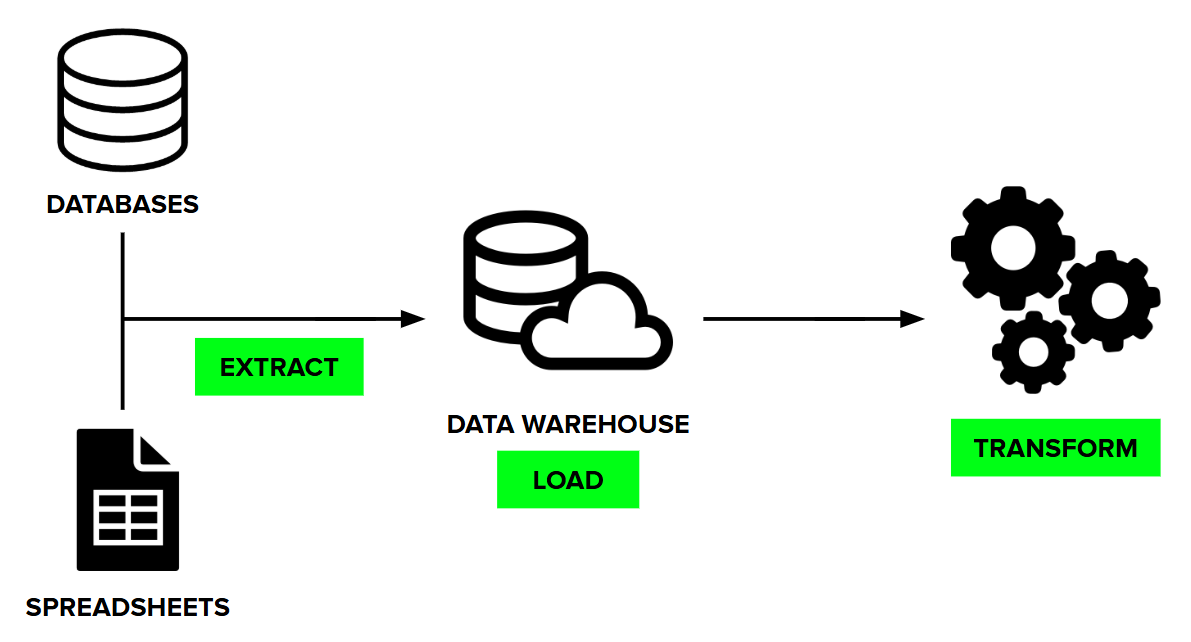
- How it works: Raw data is extracted and loaded directly into the destination system, usually a cloud data warehouse. Transformations are then applied inside the warehouse, leveraging its computing power for scalability and flexibility. This makes it easier to handle semi-structured or large volumes of data.
- Best for: Cloud-native environments where flexibility and scalability are key.
Zero-ETL
- How it works: Data is replicated directly from source systems into the target without transformations, minimising latency and complexity. The target system receives the data in its raw format, making it immediately available for querying or downstream applications. This eliminates the overhead of building and maintaining transformation logic.
- Best for: Fast, simple integrations with minimal setup.
Streaming Data Pipeline Architectures
Streaming pipelines move data continuously, enabling real-time or near real-time processing. They are essential for applications where speed matters.
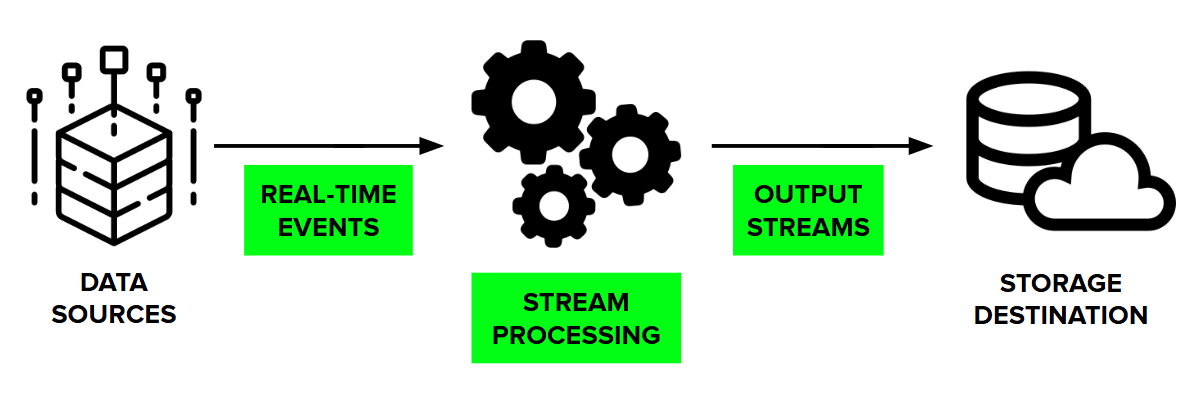
Real-Time Streaming
- How it works: Data flows continuously from sources (e.g., IoT sensors, applications, transactions) into a processing engine. The data is analysed, enriched, or filtered on the fly before being sent to destinations like databases, dashboards, or alerting systems. This allows organisations to respond to changes the moment they occur.
- Best for: Fraud detection, recommendation engines, IoT analytics.
Event-Driven / Change Data Capture (CDC)
- How it works:Pipelines are triggered by specific events such as a file upload, API call, or database row update. CDC specifically tracks changes like inserts, updates, and deletes, ensuring downstream systems always reflect the most current state. This enables near real-time synchronisation and automates workflows based on fresh data.
- Best for: Keeping systems in sync, triggering workflows when new data arrives.
Collaborative and Modern Approaches
Data Sharing Pipelines
- How it works: Instead of copying and moving data, data sharing pipelines make live datasets accessible to multiple teams or external partners. This reduces duplication, improves collaboration, and ensures stakeholders always work with the latest version of the data. Some platforms enable secure, governed sharing across organisations.
- Best for: Supply chain collaboration, healthcare data sharing, financial consortiums.
Data Mesh (Paradigm)
- How it works: Data Mesh is less about specific tools and more about governance, culture, and decentralisation. It decentralises pipelines by giving domain-specific teams ownership of their own data products. Instead of relying on one central data team, each business unit builds, manages, and serves its data in a standardized, interoperable way. This shifts focus from technology alone to governance, culture, and scaling across large organizations.
- Best for: Large organisations with distributed teams and complex data domains.
Comparison Table
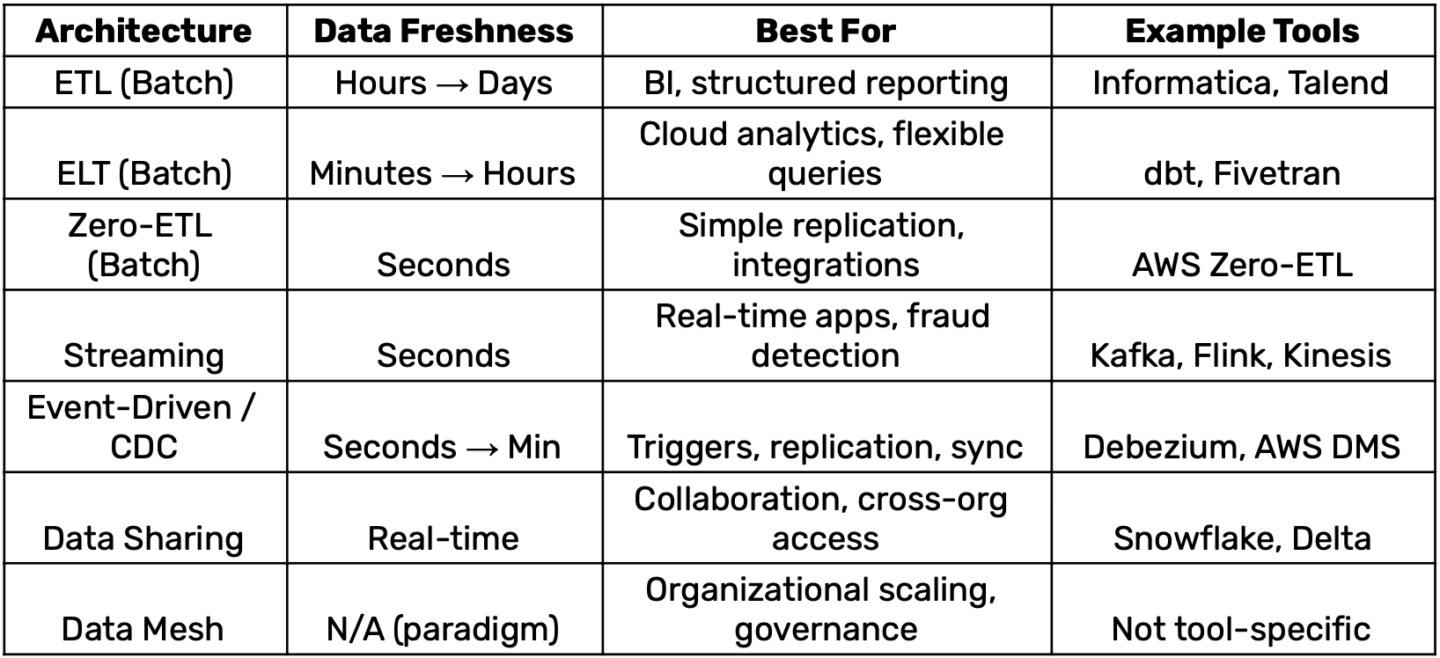
Best Practices
When designing data pipeline architectures, scalability should be one of the first considerations. The ability to handle growing data volumes without major redesigns is essential for long-term success. Monitoring and observability also play a crucial role: by tracking pipeline health, latency, and errors, teams can detect issues before they impact downstream applications.
Data quality and security must be enforced at every stage, from validating records at ingestion to encrypting data in transit and at rest.
Finally, cost optimisation should not be an afterthought. Leveraging serverless technology, autoscaling features, or pay-per-use pricing models helps organisations control expenses as workloads fluctuate.
Choosing the Right Architecture
The “right” pipeline depends on your needs:
- Batch pipelines are best when data doesn’t need to be real-time and stability matters.
- Streaming pipelines are best when every second counts.
- Zero-ETL is gaining traction in cloud-native setups.
- Data Sharing and Data Mesh address organisational challenges—governance, collaboration, and decentralisation.
For many companies, a hybrid approach works best: batch for heavy workloads, streaming for real-time use cases, and data-sharing models for collaboration.
Real-world data pipeline architecture examples
Subsea 7 – Logistical Operations Custom Data Pipeline Example (Energy Industry)

For Subsea7, we have built a solution that encompasses:
- An onshore application for entering the ship log data that runs on vessels.
- A central onshore application for collecting the said data, collating it, and displaying it in various dashboards.
- A project management application, for defining and managing checklists that serve as templates for tasks that every project needs to be completed.
- An application for the equipment transportation system to streamline every aspect of the logistical process.
- A system for streamlining and speeding up the process of project budget estimation and resource task assignments.
This required creating a distributed system that functions both onshore and offshore. Each ship receives only the data that is relevant to it. Both the automated and manual transfer of data is enabled.
The custom data pipeline architecture that we have created follows the business-oriented logic: When is the data going to be transmitted? Is an internet connection available? Is the bandwidth limited? The solution is a combination of different data pipeline models.
Sandoz – Real-time Data Pipeline Connecting With Multiple External Services (Pharma Industry)
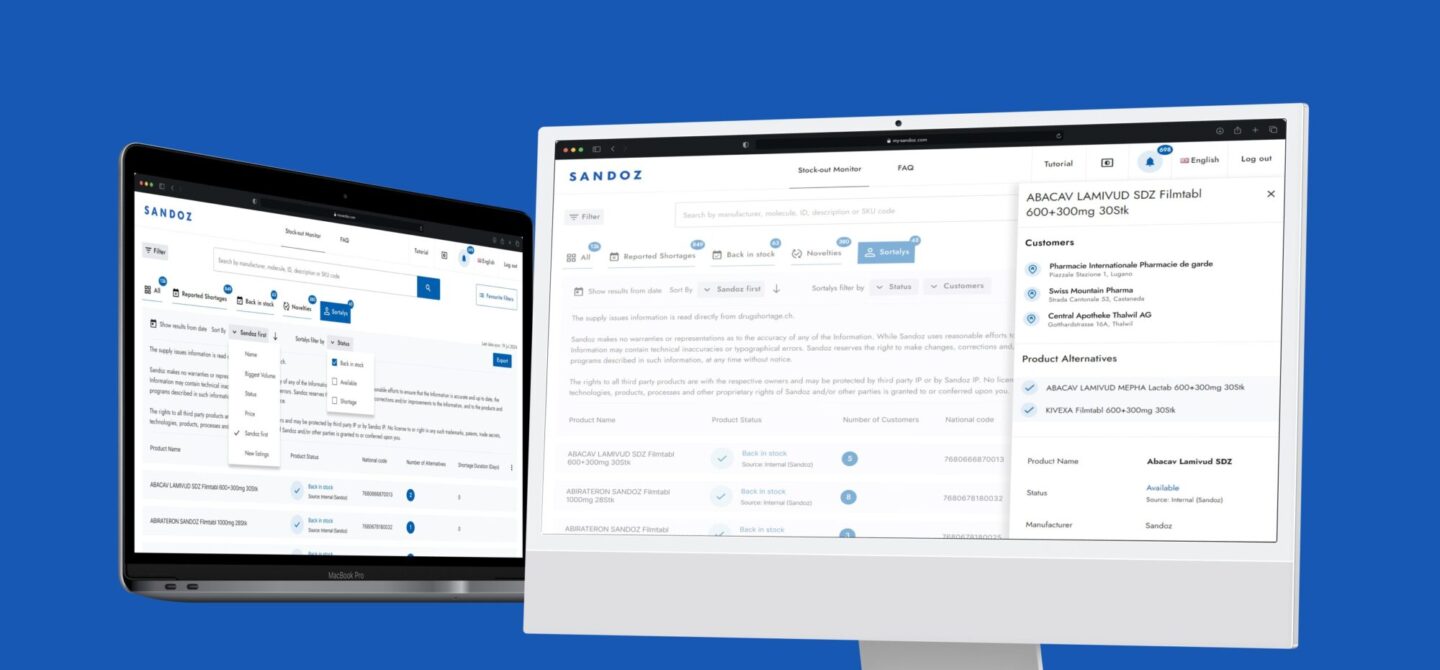
The Sandoz Stockout Monitor web application’s purpose is to help pharmacists have the right information at the right time, giving the right support to their patients. While this may sound simple, it was a challenge in terms of:
- Connecting with numerous external services
- Managing the substantial data load that required constant synchronisation
- Ensuring real-time data accuracy and reliability
This project demanded meticulous data pipeline architecture planning in order to maintain a seamless performance.
Final Thoughts
Data pipeline architectures have evolved from traditional ETL into a spectrum of batch, streaming, and collaborative models. By understanding the strengths, limitations, and use cases of each, you can design pipelines that are scalable, cost-effective, and future-proof.
Ready to unlock the full potential of your data? Get in touch with us and let’s start building the right pipeline architecture tailored to you and your business.
Give Kudos by sharing the post!
ABOUT AUTHOR

Petar Apolonio
Manager of Data Science Excellence


